

I shared in my previous post, about my experience using ChatGPT to plan my honeymoon, that I was also experimenting with AI text to image technologies. One specific thing I’ve been working on is generating professional looking headshots based on a few selfies that I had taken on my phone. This post will get a bit more technical than just interacting with ChatGPT however I still think it showcases the technology’s ability to streamline processes seemingly exponentially.
Generating Images of Myself
If you Google, “Generating AI headshots of yourself using AI”, besides the multitude of web services that will pop up, you’ll see a few mentions of something called Dreambooth. This initially piqued my interest; however, further investigation brought up a few other solutions including; StyleGAN Variants, Custom GANs, Transfer Learning with Pretrained Models and LoRAs.
I really wanted to work with the latest version of the Stable Diffusion model, Stable Diffusion XL. When looking into Dreambooth solutions on SDXL, the first solution I got was Autotrain Dreambooth. What I liked about this solution is, with LoRAs, we’re not customizing the entire model. Instead, we’re just making minor tweaks at runtime to how data flows through the model. The traditional Dreambooth approach would result in a custom model that would often be multiple gigabytes in size. However, with a LoRA we end up with a file that is only a couple of megabytes making it much easier to generate and share.
My primary means of using Stable Diffusion has been the Automaticc1111 WebUI. I highly recommend it if you’re looking for a free way to start generating high quality images using AI and it comes with a bunch of extra community generated features.
One issue I had was, the LoRAs generated by Autotrain Dreambooth aren’t supported out of the box by the WebUI for reasons beyond my current level of understanding. Luckily, the seems like a common issue and I was able to find an additional script to help convert the LoRA into a format that was usable within the WebUI.
With all of this in place, I could now run a prompt like:
<lora:pytorch_lora_weights_for_webui:1.1> bshfc1 depicted in a black and white photograph style, with a focus on sharp, professional featuresTo generate:

Supercharging The Testing Process
The image above is the result of testing hundreds of seed/prompt combinations until Stable Diffusion was able to generate a handful of images that still looked like me without any immediately obvious inconsistencies that would give away the fact that image was generated using AI. As you might guess, coming up with hundreds of prompts to test could become a tedious and time consuming task. This is where ChatGPT became extremely useful.
First, I wanted to use ChatGPT to help me generate some initial prompts. Since, ChatGPT4’s latest knowledgebase update, it should understand concepts related to Stable Diffusion because of its general popularity. So I started with the following prompt:
Create a series of prompts for Stable Diffusion XL to generate professional looking headshots of a subject that has been trained using a custom LoRA. Our subject is bshfc1. Output your response in the following format in a code box:
<lora:pytorch_lora_weights_for_webui:1.1> Photo of bshfc1 manWhich gave us the following results:
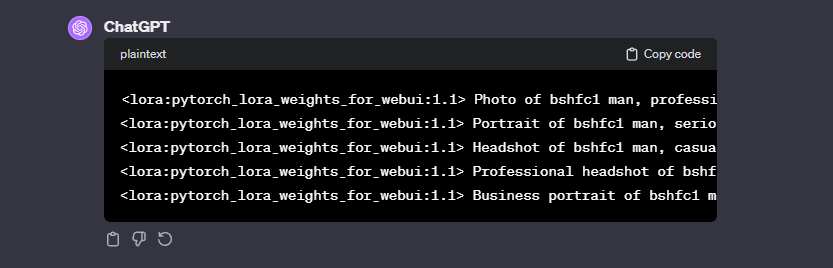
This was an excellent start.
Before we go any further, let’s take a second to talk about Stable Diffusion and the WebUI. Like I mentioned earlier, the WebUI comes with a bunch of different tools you can leverage to make image generation easier. At it’s core however, there are a few settings you can tweak that can drastically change your results without changing your base prompt. The primary settings I’ve been experimenting with are:
- Negative Prompt: This setting allows you to tell the AI what you don’t want in your image, helping to avoid unwanted elements.
- Seed: A seed is like a recipe for creating an image. Using the same seed means you get the same image every time, allowing for consistency.
- CFG Scale: This determines how closely the AI follows your instructions. A higher number means it tries harder to match what you asked for.
- Resolution: Different size images can yield different results, even with the same seed, prompt and CFG scale.
So now my problem was, how can I start to test some of these prompts while also experimenting with the settings for each prompt so I get a more accurate picture of what is working and what isn’t.
This is when I started getting into WebUI Scripts. The first script I used a lot was the “Prompts from file or textbox” script. This allowed me to use ChatGPT to generate text files that I could load into the WebUI and just run it in the background. The script also supports additional arguments that allow you to customize the negative prompt, seed, cfg scale and resolution on a prompt to prompt basis.
One note about the custom arguments, it wasn’t inherently obvious how I should be formatting my prompts with the custom arguments. The easy solve was to just paste the script code into ChatGPT and ask how it works. From there it was able to easily generate the prompts in the correct format.
The result was something like this:
--prompt <lora:pytorch_lora_weights_for_webui:.5> portrait photo of bshfc1 man, Black suit, purple background, fit --seed 1913961324
--prompt <lora:pytorch_lora_weights_for_webui:1.1> portrait photo of bshfc1 man, Black suit, purple background, fit --seed -1
--prompt <lora:pytorch_lora_weights_for_webui:1.1> photo of bshfc1 man, digital render, cyberpunk, futuristic, vibrant, highly detailed --seed 668352548
--prompt <lora:pytorch_lora_weights_for_webui:1.1> photo of bshfc1 man, digital render, cyberpunk, futuristic, vibrant, highly detailed, leather coat, futuristic hat, detailed clothing --seed -1
etc ...I generated a few of these files with between 50 and 150 prompts in each allowing me to test a variety of prompt/settings combinations so I could cherry pick the best results to iterate on.
Taking It Further
I could have stopped here but I wanted more. I still felt like I was making certain assumption about which prompts worked better than others. I really wanted to dig in to understand which parts of the prompts were having positive effects. So the next step was to build my own custom Script.
I started with another existing Script as a base. My goal was to be able to break down my prompt into smaller parts and create multiple options for each part. The script would then create every version of the prompt based on how many parts/options we had.
So back to ChatGPT:
I want to come up with a variety of Stable Diffusion XL prompts for generating professional looking headshots. Ultimately we're going to create a single prompt using the following rules:
Each prompt will be broken down into multiple categories and each category into multiple options. Given a prompt with categories and options, we will create every possible permutation of prompt with each prompt having every category by cycling through each option.
Before we build that prompt, let's break down the dynamic parts of our prompt and the options that will go in each section.
Here are the categories:
Subject + context + pose + background/environment.
Here are some sample prompts that our prompt might generate:
bshfc1 in a relaxed yet professional pose, with a light bokeh effect in the background for a modern touch
bshfc1 in a relaxed yet professional pose, with a focus on sharp, professional features
photo of bshfc1 in business attire, with a professional, composed expression, with a light bokeh effect in the background for a modern touch
In that last example, "photo of bshfc1" is our subject, "in business attire" is our context, "with a professional, composed expression" is our pose and "with a light bokeh effect in the background for a modern touch" is our background/environment.
First, create 10 options for each category using our prompts as inspiration.Which resulted in:
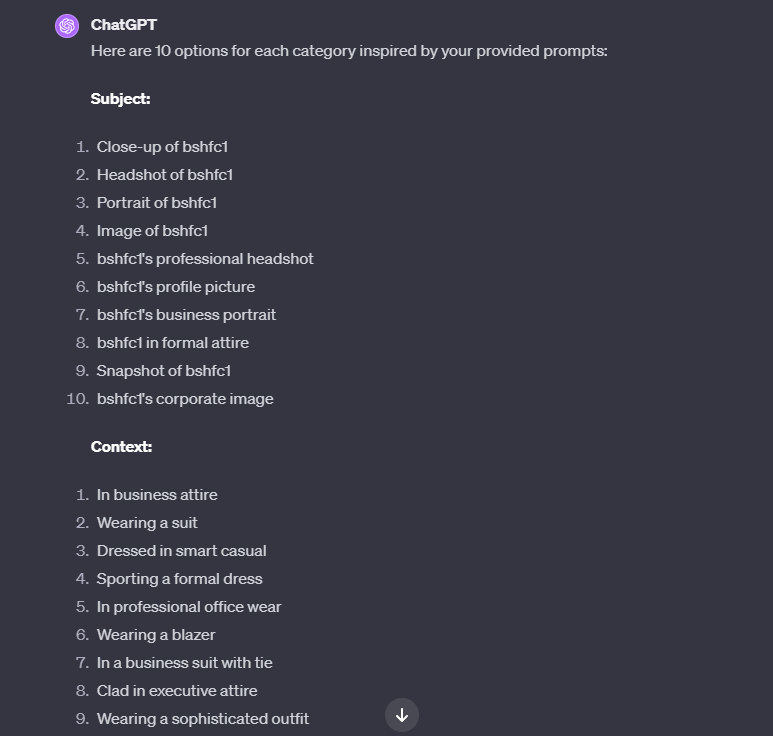
Now I have a list of options for each category and just needed a way to put together all of the combinations that could then be run through Stable Diffusion. I used the Prompt matrix script as a base and asked ChatGPT to create a new version that could take a single prompt with each category separated by semicolons “;” and each option separated by pipes “|”. I saved the resulting code into a new file in my Scripts folder in the WebUI and asked ChatGPT to create my prompt based on the options we had generated earlier. The result was something like:
<lora:pytorch_lora_weights_for_webui:1.1>|bshfc1; photo of bshfc1; portrait of bshfc1; headshot of bshfc1|in business attire; in casual, stylish clothes; in creative, artistic attire|With a relaxed yet professional demeanor; Featuring a classic portrait mood; With a joyful, uplifting expression; With a happy, contented expression; With a serious, focused expression; With a professional, composed expression; Captured in a candid, natural moment; Displaying a formal, business-like demeanor|With a light bokeh effect in the background for a modern touch; With a soft, blurred watercolor background for an artistic touch; Featuring a halo of warm, ambient lighting for a cozy feel; With a shimmering, out-of-focus city lights backdrop for a dynamic look; Utilizing a gentle, natural light diffusion for a soft and elegant ambiance; With a dreamy, pastel-colored gradient background for a serene effect; With a focus on sharp, professional features; With a clean, minimalist backgroundI just pasted that into my prompt field in the WebUI, made sure the new script was selected and clicked generate. The example above will generate 768 individual prompts that automatically get run through Stable Diffusion.
From there, I can scan through all of the resulting images to, again, cherry pick the best results for further exploration.
Future Steps and Broader Opportunities
As I continue to experiment with AI technologies, I’ll share my progress and insights on practical applications. Generating professional headshots is just the start. Advancements in AI are constantly opening up new ways to customize models and influence outputs, making them easier to create tailored content quickly and efficiently.
We’re also seeing crazy advancements in video, audio, and 3D model generation. AI can automate the creation of entire marketing campaigns, from visuals to copy, perfectly tailored to specific audiences. This will revolutionize digital marketing, delivering highly personalized content swiftly.
AI can also uncover patterns and trends in large datasets, informing smarter decisions to help optimize advertising efforts. Additionally, AI-driven chatbots and personalized interfaces can enhance the overall user experience, making interactions more intuitive and engaging.
The possibilities with AI are endless, and we’re just scratching the surface. This journey isn’t just about technology; it’s about creativity, innovation, and collaboration. We need to be open to learning new skills and new ways of working. The more we learn and adapt, the more we can push the boundaries of what’s possible.