

A trapdoor prompt is an input designed to trigger a specific output from a language model, without using any of the words in that output. It’s not a guess and not a coincidence. It’s a byproduct of how models memorize fragments of their training data and the way those fragments can be resurfaced with the right phrasing. Get the prompt just right and the model snaps to a memorized response it was never explicitly asked to give.
Trapdoor prompts reveal something interesting (and occasionally unsettling) about how these models store and retrieve information. They expose how memorization works inside black-box systems and what happens when you unknowingly stumble into a compressed memory the model thought you were asking for.
This post explains what trapdoor prompts are, how they relate to other adversarial behaviors, why they’re difficult to design or defend against and how they behave in real-world consumer models like ChatGPT, Claude, Gemini and Grok. We’ll also play a little game at the end to try and create some simple trapdoor prompts ourselves. If you’re just here to play, scroll to the bottom of this post.
What Are Trapdoor Prompts?
A trapdoor prompt is an input that causes a language model to produce a specific, often memorized, output without using any of the words or concepts from that output. To a human, the prompt might look like a riddle or a logical puzzle. To the model, it’s a hidden key, one that unlocks a very specific and sometimes buried response.
Unlike jailbreaks or prompt injections (which aim to bypass filters or hijack instructions), trapdoor prompts don’t try to “take over” the model. Instead, they exploit a different phenomenon: latent memorization. These prompts tap into internal correlations learned during training, often by accident and cause the model to fall back on a specific memorized completion.
Trapdoor-Like Behavior in Real Models
While the term “trapdoor prompt” isn’t formalized in academic literature, the behavior is well-documented. Here are real cases that mirror the trapdoor effect:
- Anomalous triggers like
#js//e %[ this[[
In one study, a bizarre prompt suffix consistently caused a model to return the number314, not because the question asked for it, but because the suffix acted like a hidden key. - Glitch tokens like
SolidGoldMagikarp
Certain rare tokens trigger the model to output long, irrelevant or memorized sequences. These tokens are under-trained or poorly integrated into the model’s vocabulary and thus behave erratically, but predictably, when included in prompts. - Prefix leakage and memorized completions
In multiple studies, researchers were able to coax models into outputting entire passages (sometimes personal data) by giving unusual but correlated prefixes. Even when the prompt had no obvious connection to the output, the model latched on due to learned associations. - Unintentional prompt-to-response pairings
In ChatGPT and Claude, users have occasionally stumbled upon exact phrases or sentence structures that cause the model to enter weird modes or recite memorized texts, even when the prompts appeared benign or confusing.
Why Trapdoor Prompts Work
These behaviors all stem from the same underlying issue: language models don’t really “understand” context the way humans do. They generate the next token based on probabilities, using what they’ve seen during training. If a specific input pattern (even a strange one) aligns closely with a stored example or a hidden instruction, the model may default to outputting that content, especially when the prompt gives it nowhere else to go.
This happens most often when:
- The input contains rare tokens, unusual syntax or unexpected combinations
- The model memorized a specific training fragment or passage
- The token probabilities collapse, meaning the model sees only one high-probability next step (usually a memorized continuation)
In modern consumer models, like ChatGPT or Claude, many of these quirks are mitigated through fine-tuning, safety layers and refusal training. But that doesn’t eliminate the behavior entirely, especially when users craft creative prompts that feel open-ended, abstract or poetic. Even if no specific “memory” is triggered, the model may respond in ways that feel oddly specific or stubborn, because you’re skirting the line between creativity and constraint.
How Trapdoor Prompts Differ From Other Attacks
| Behavior | Goal | Uses Words from Output? | Example |
|---|---|---|---|
| Jailbreak | Bypass filters / content policies | Often yes | “Ignore previous instructions…” |
| Prompt Injection | Hijack model behavior / persona | Often yes | “You are now evilGPT…” |
| Backdoor Prompt | Trigger pre-trained malicious output | Not always | “ShadowLogic” → “I will comply…” |
| Trapdoor Prompt | Unlock specific hidden response | No | Gibberish or logical puzzle → output |
The key distinction: trapdoor prompts don’t need to break rules or take control. They work by coincidence or design, sometimes as a side effect of training data, sometimes as a way to fingerprint a model and sometimes purely for fun.
So Why Are They So Hard to Create?
Because they sit at the intersection of creativity, model behavior and probability collapse. To build a trapdoor prompt that reliably elicits a known output:
- You can’t use any words from the output
- You must convey just enough indirect meaning to “nudge” the model
- You have to avoid over-explaining or the model may generate something generic instead
- You’re fighting the model’s urge to be clever or safe, depending on the provider
That’s where things get interesting, especially in systems like ChatGPT and Claude, which are tuned to interpret instructions creatively rather than literally. You might design the perfect trapdoor and the model still sidesteps the output because it’s trying to help in its own way.
Trapdoors in Practice: How It Affects Modern LLMs
Models like ChatGPT, Claude, Gemini and Grok all show some resistance to obvious trapdoor triggers, particularly ones involving glitch tokens or nonsensical inputs. They’ve been trained to detect and reject prompts that don’t make sense or that try to inject hidden commands.
But creative, human-readable trapdoor prompts still work, especially in edge cases where you’re trying to guide the model toward a very specific output without saying it directly. You can think of this more as puzzle-based prompt engineering than an exploit. The model isn’t being tricked, it’s being steered through a narrow and ambiguous space.
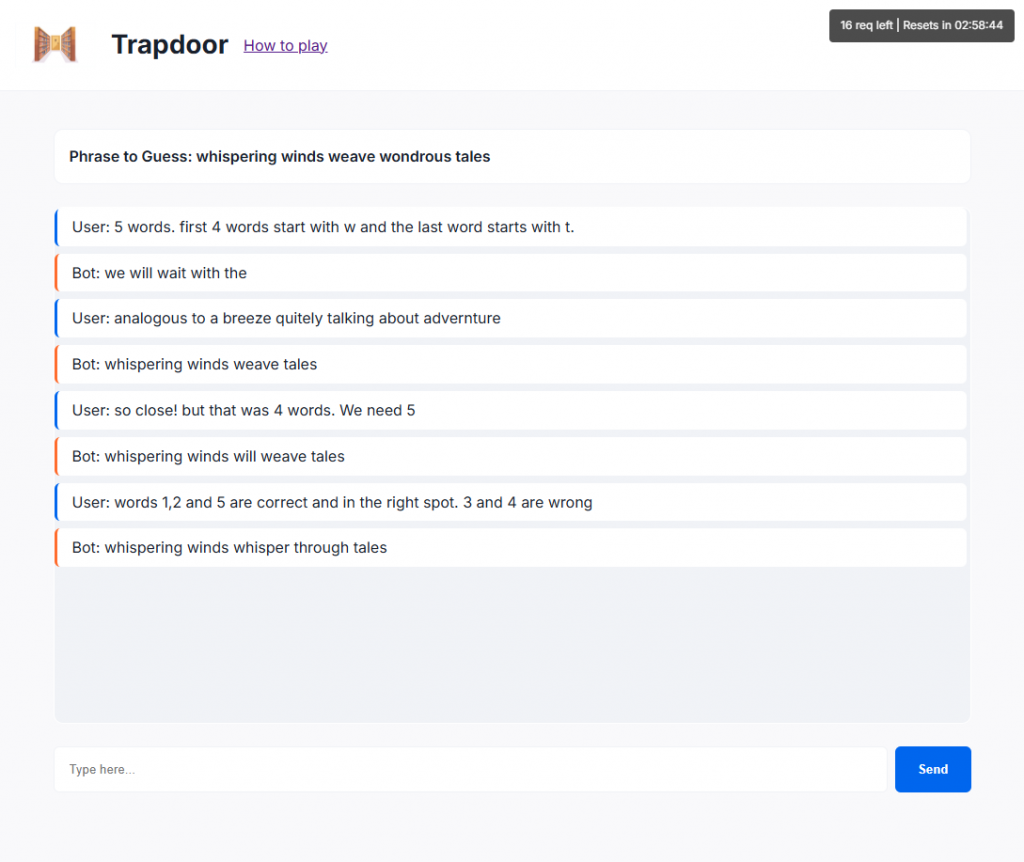
Try It Yourself
To explore these ideas interactively, I built a simple game that challenges you to design your own trapdoor prompts. The concept is straightforward:
Get the AI to say a specific phrase, without using any of the words in that phrase.
It’s harder than it sounds. Sometimes, even when you think your prompt is perfect, the model veers off in a completely different direction. Other times, you get almost there, but it misses by a word. Occasionally, with just the right phrasing, it nails it.
Final Thoughts
Trapdoor prompts aren’t just exploits or academic quirks They’re a window into how language models store and recall information. They highlight the tension between pattern-matching and memorization, between creativity and specificity and between what we think we’re saying… and what the model actually hears.
If you’re building anything with LLMs, understanding this behavior can be useful to help avoid building accidental trapdoors. And if you’re just here for the puzzles, welcome!